
Run your own free Stock Checker - Check if sought-after items are in stock online
Here is the stock checker that I created while trying to buy an Nvidia RTX 3080. I will show you how to set it up for yourself to monitor online stores for stock.


The Problem
While looking for parts for a PC online during the Nvidia RTX 3080 drought of late 2020, I really wanted a way to automate checking various websites to see if there were any RTX 3080s in stock / available to purchase.
Out of the box solutions
There are some solutions that exist online that use browser plugins or will do the checking for you on their servers.
If they have a free solution, it is usually very limited, like distill.io which allows only 30 notifications emails each month. I tried using them but I burnt through the 30 emails pretty quickly with 30 false positives in a couple of days.
My Solution
I decided to build my own solution using NodeJs and Selenium webdriver.
Selenium webdriver uses your local browser to visit the various sites and has tools to pull data from the pages it visits.
With that in mind, I created a package to visit predefined sites, retrieve text from a specified element and compare it to a specified value.
When there is a difference, it can notify you via Pushover or Gmail, or both.
My package is available on GitHub.
 jaydlawrence
jaydlawrence
Running it yourself
If you would like to use the package yourself, the instructions are available in the README.md of the project.
If you are not familiar with GitHub or NodeJs apps, here is a quick summary of the extra steps:
Download the project from GitHub.
It should be available as a zip archive, download that and extract it.
Install NodeJs
Installing NodeJs will differ depending on your operating system.
Check their website for more details.
https://nodejs.org/en/download/
Use NPM to install the dependencies
When node is installed you will have access to the package manager that comes with it, called NPM.
Use whichever shell or command prompt you have access to, to navigate to the project directory and then install with:
npm install
Follow the README.md instructions
From here, you should be able to follow the instructions in the project documentation.
Getting the XPaths that you need
In Google Chrome, there is a built in tool to get the XPath from a particular element.
Start by right-clicking on the element you want to monitor and select, inspect.
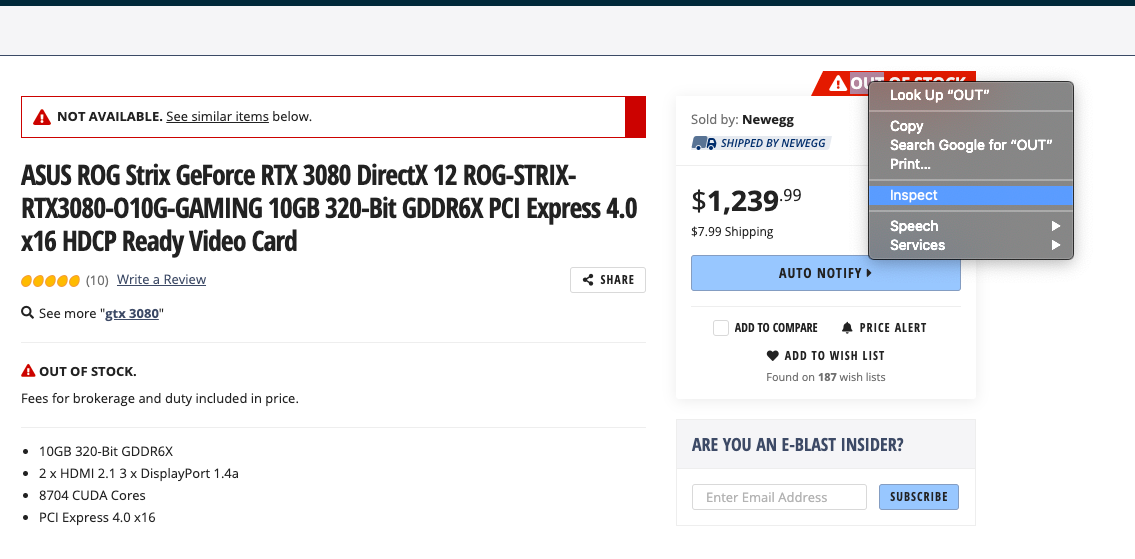
Then it reveals the HTML code for the element. Right click on this element and select copy and then Copy XPath.
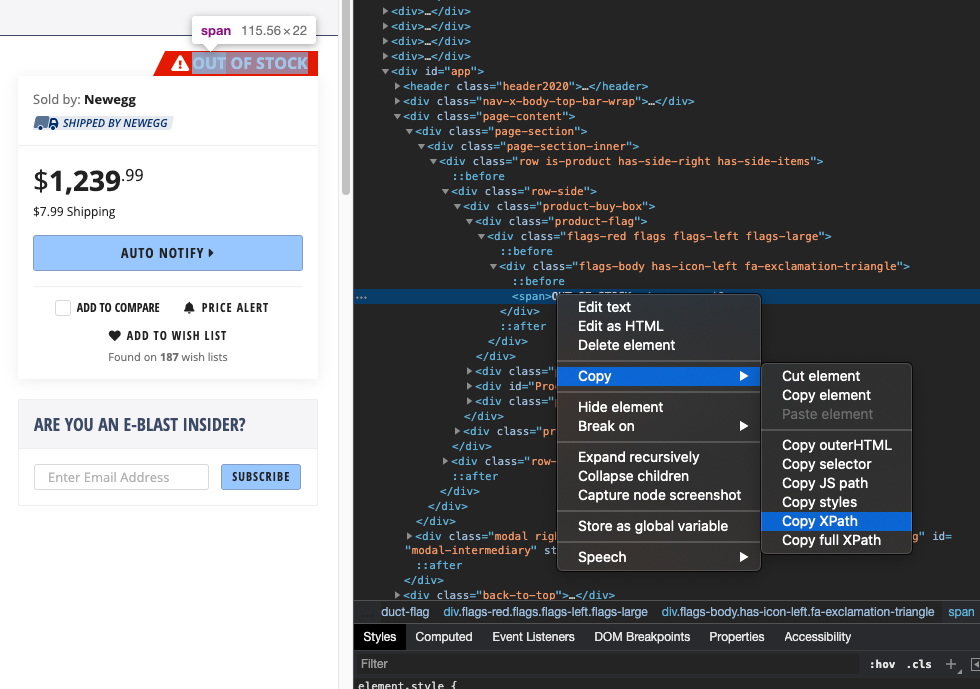
You can then paste this in the config.
{
"url": "https://www.newegg.ca/asus-geforce-rtx-3080-rog-strix-rtx3080-o10g-gaming/p/N82E16814126457",
"xPath": "//*[@id=\"app\"]/div[2]/div[1]/div/div/div[1]/div[1]/div[1]",
"expected": "OUT OF STOCK",
"description": "New Egg - ASUS RTX3080 Strix"
},
You will have to escape any quotation marks in the XPath.
So if there is a " in the middle of the XPath, replace it with \".
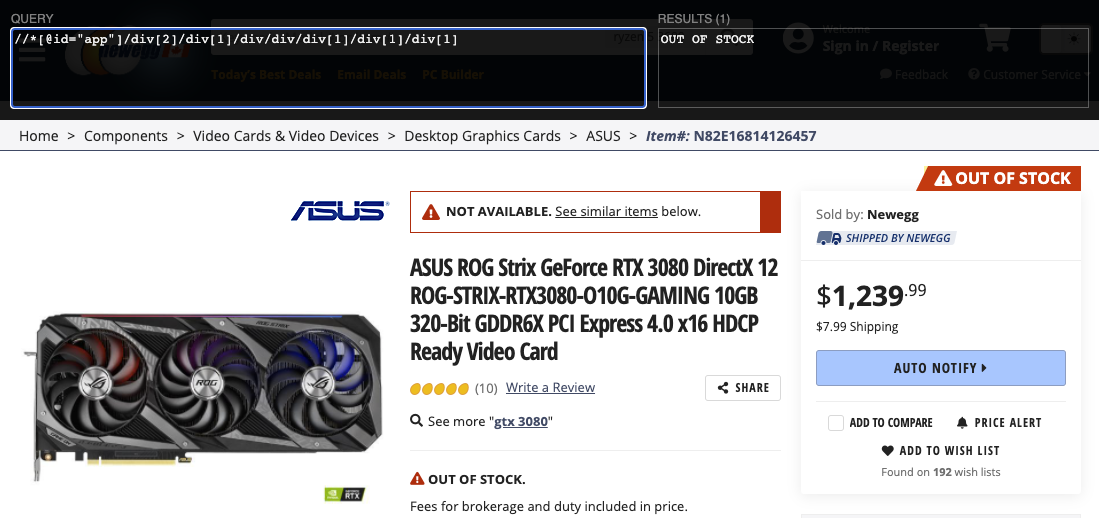
If you want to double check the XPath and the text value that it gets, you can use the Chrome extension called XPath Helper.

If you open the extension on your target page and paste your XPath in and it will show what text it finds.
Tips for setting the Cron
Wikipedia has a good overview of what the Unix Cron is and how it works.
https://en.wikipedia.org/wiki/Cron
When setting the cron to run your search, keep in mind that some websites will block your computer if you hit them too often.
I have found that setting it to 5 minutes works well for me.
*/5 * * * * /path_to_script/stock-checker/run.sh



